

Amazon Bedrock Deep Dive: Your Gateway to Foundation Models on AWS
If you've been following along with this blog series, you know I'm a Microsoft person learning AWS. I've spent years in the Azure ecosystem, so when I first heard about Amazon Bedrock, my brain immediately went "Oh, this is like Azure OpenAI Service!".
And honestly? That's not a terrible comparison. But Bedrock has some tricks up its sleeve that make it uniquely AWS. Understanding Bedrock is absolutely critical for passing the AWS AI Practitioner exam. Domain 3 (Applications of Foundation Models) makes up 28% of your exam score, and Bedrock is the star of that show.
What Is Amazon Bedrock?
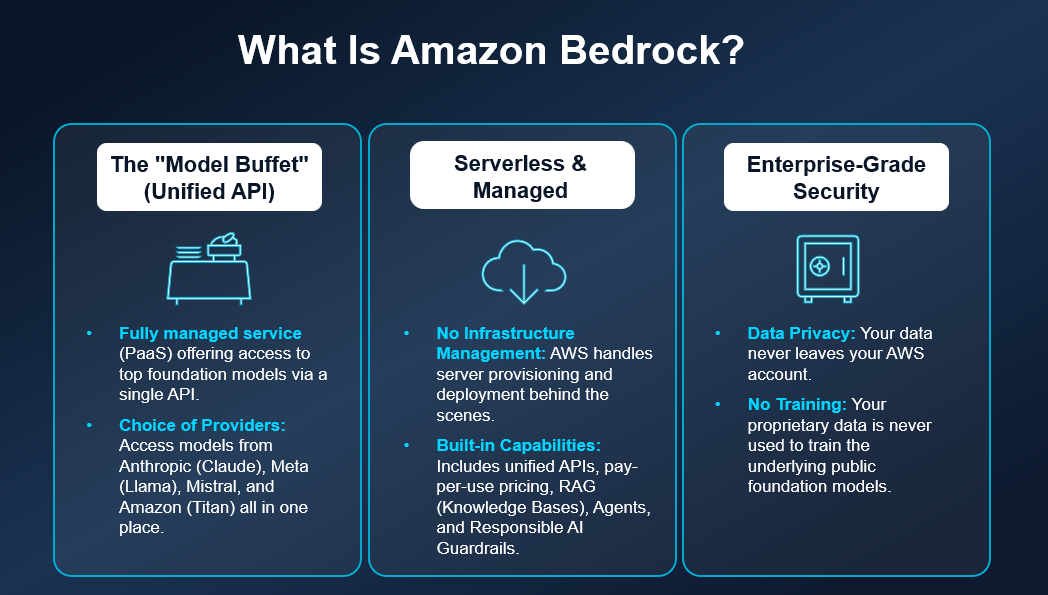
Here's the simplest way I can explain it: Amazon Bedrock is a fully managed service (think PaaS) that gives you access to foundation models (FMs) from multiple AI companies through a single API. Think of it as a model buffet. Instead of going to Anthropic's house for Claude, Meta's house for Llama, and Amazon's house for Titan, you just show up at the Bedrock restaurant and order whatever you want.
The "fully managed" part is key here. You don't have to worry about provisioning servers, managing infrastructure, or figuring out how to deploy these massive models. AWS handles all of that behind the scenes. You get unified APIs for access, pay-per-use pricing, and a bunch of out-of-the-box features like RAG, LLM agents, and responsible AI controls.
Here's something that trips people up: when you use a foundation model through Bedrock, AWS makes a copy of that model available only to you. Your data never leaves your account, and none of your data is used to train the underlying foundation model. This is huge for enterprises worried about data privacy. Your proprietary information stays proprietary.
Pro Tip: Remember this: Bedrock provides serverless access to foundation models. No infrastructure management required. Your data is isolated and never used to train the base models. This is one of those "gimme" questions if you see it.
The Model Lineup: Choosing Your Fighter
One of Bedrock's biggest selling points is model choice. Unlike some platforms that lock you into a single provider, Bedrock lets you pick from several model families. Here's the list of options:
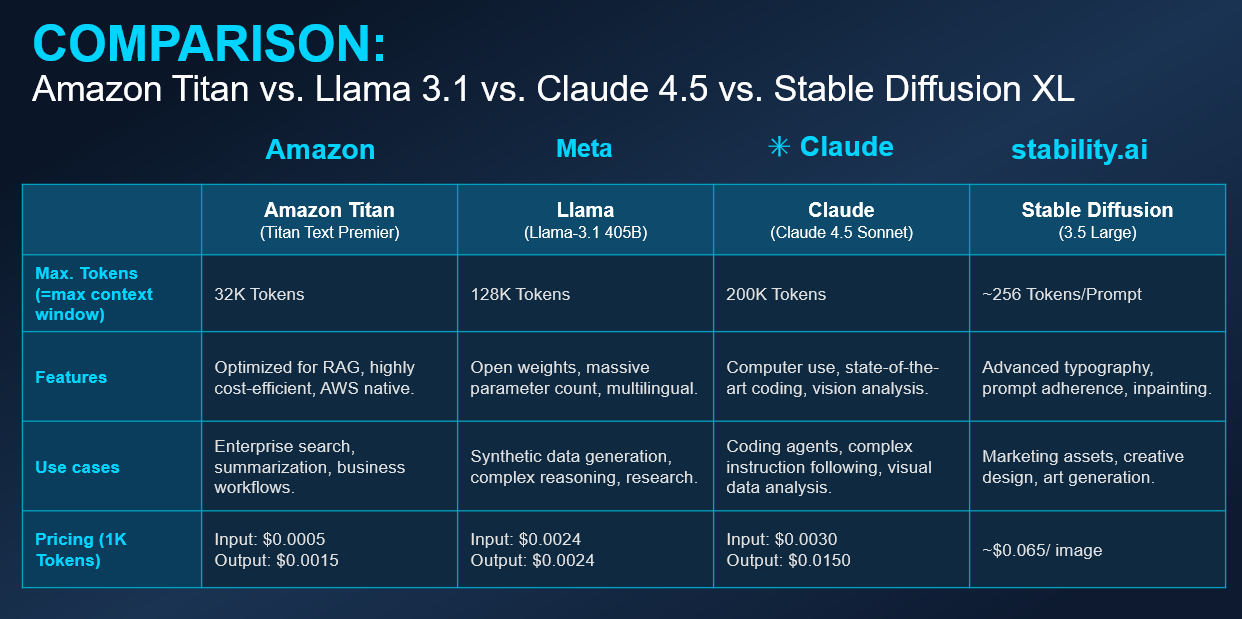
Amazon Titan: AWS's homegrown model family, and since this is an AWS certification we're studying for, expect Titan to show up on the exam. A lot. Titan is described as a high-performing foundation model directly from AWS. You've got Titan Text for language tasks, Titan Embeddings for converting text into vectors (super important for RAG, which we'll get to), and Titan Image Generator for creating images. A key selling point is that Titan can be customized with your own data through fine-tuning. The exam loves to test whether you know Titan is Amazon's own model versus a third-party offering.
Amazon Nova: A portfolio of AI offerings. These represent the next generation of multimodal foundation models with improved performance. Nova Forge (announced at re:Invent 2025) is a new service for creating your own frontier models, while Nova Act is designed to help you build agents that automate browser-based UI workflows. You can tryout Nova foundation models here. For a deeper look at Nova Agents, watch this Nova Act Video from AWS.
Anthropic Claude: Claude is known for being helpful, harmless, and honest. It excels at analysis, coding, math, and following complex instructions. Here's a practical consideration: Claude can take more tokens (has a larger context window), which means it has more "memory" and can handle bigger inputs. This matters when you're dealing with a large code base or need to read an entire book and ask questions about it. The Claude family includes different sizes, from the efficient Haiku to the powerful Opus.
Meta Llama: Brings open-source power to Bedrock. Llama models are popular in the AI community because Meta released the weights publicly. On Bedrock, you get the convenience of managed deployment without having to set up Llama yourself.
Stability AI: Your go-to for image generation with Stable Diffusion models.
Mistral AI: High-performance, efficient models that are gaining massive traction.
Cohere: Specializes in enterprise search and retrieval applications. Their Command models are solid for business use cases.
AI21 Labs Jurassic: Focuses on language tasks and offers good multilingual support.
Exam Tip: For the exam, you need to know which provider offers which type of model. They love asking questions like "A company needs to generate images from text descriptions. Which Bedrock model provider should they use?" (Answer: Stability AI or Amazon Titan Image Generator, depending on the specific requirements.)

Choosing the right Model
Here's where it gets interesting, and where a lot of exam questions live. Choosing a foundation model isn't just about grabbing the most powerful option available. There's no single "best" model. It comes down to testing and balancing multiple factors based on your business needs.
Performance Requirements and Latency matter when you're building real-time applications. A customer service chatbot can't wait 30 seconds for a response. Smaller, faster models like Claude Haiku or smaller Llama variants give you speed when you need it. The exam might describe a scenario requiring "fast responses" and expect you to choose accordingly.
Cost Constraints are always a consideration, and here's a key insight: smaller models are generally more cost-effective, but they usually "know less things." It's a balancing act. Foundation models charge based on input and output tokens (more on that later). A model that costs 10x more per token might not be worth it if a cheaper model handles your use case just fine.
Context Window determines how much text the model can consider at once. If you're analyzing long documents, you need a model with a large context window. This is why Claude is often recommended when you need to send a big context window, like when dealing with a large code base or reading an entire book to ask questions about it. The exam tests this concept.
Modality refers to what types of input and output the model supports. Some models are text-only. Others are multimodal, meaning they can take a wide combination of input types (audio, text, video together) and give you various types of outputs (images, audio, video, text) all at the same time. If a question mentions needing to process multiple input types simultaneously, think multimodal.
Customization Options vary by model. Some models offer different levels of customization, and some can be fine-tuned while others cannot. Amazon Titan, for example, can be customized with your own data.
Licensing Agreements and compliance requirements also factor in. Different models have different terms, and enterprises often have specific compliance needs that limit their choices.
Task Fit should ultimately drive your decision. Need code generation? Some models excel at that. Need creative writing? Different specialty. The exam will give you scenarios and expect you to pick the appropriate model based on requirements.
The honest truth is that all these models are starting to converge in capabilities. They're all getting better at the same things. So, for real-world use, it often comes down to testing. But for the exam, know the differentiating factors and match them to scenarios.
Inference Parameters: The Knobs and Dials
When you call a foundation model, you don't just send your prompt and hope for the best. You can tune several parameters to control the output. The exam absolutely tests these, so pay attention.
Temperature: Controls randomness.
0: Think of an accountant giving tax advice; focused and predictable.
1: Think of a creative writing friend brainstorming; creative and varied.
Top P (Nucleus Sampling): Another way to control randomness. Instead of temperature's approach, Top P limits the model to only consider tokens whose cumulative probability adds up to P. A Top P of 0.9 means the model only considers tokens that together represent 90% of the probability mass. Lower values make responses more focused.
Top K: Limits the model to only consider the K most likely next tokens. If Top K is 50, the model picks from the 50 most probable options for each token. This prevents the model from going off the rails with unlikely word choices.
Max Tokens: Sets a hard limit on response length to control costs and rambling.
Stop Sequences: Tells the model exactly when to stop generating. If you're building a Q&A system, you might set a stop sequence, so the model stops after answering instead of continuing to generate additional content.
Watch Out: If a question describes a scenario where responses are "too creative" or "making things up," the answer probably involves lowering temperature or adjusting Top P/Top K values.
Knowledge Bases and RAG: Teaching Models New Tricks
This is where Bedrock gets really powerful, and it's heavily tested on the exam.
Foundation models are trained on data that has a cutoff date. They don't know about your company's internal documents, your product catalog, or last week's policy changes. Retrieval Augmented Generation (RAG) solves this problem.
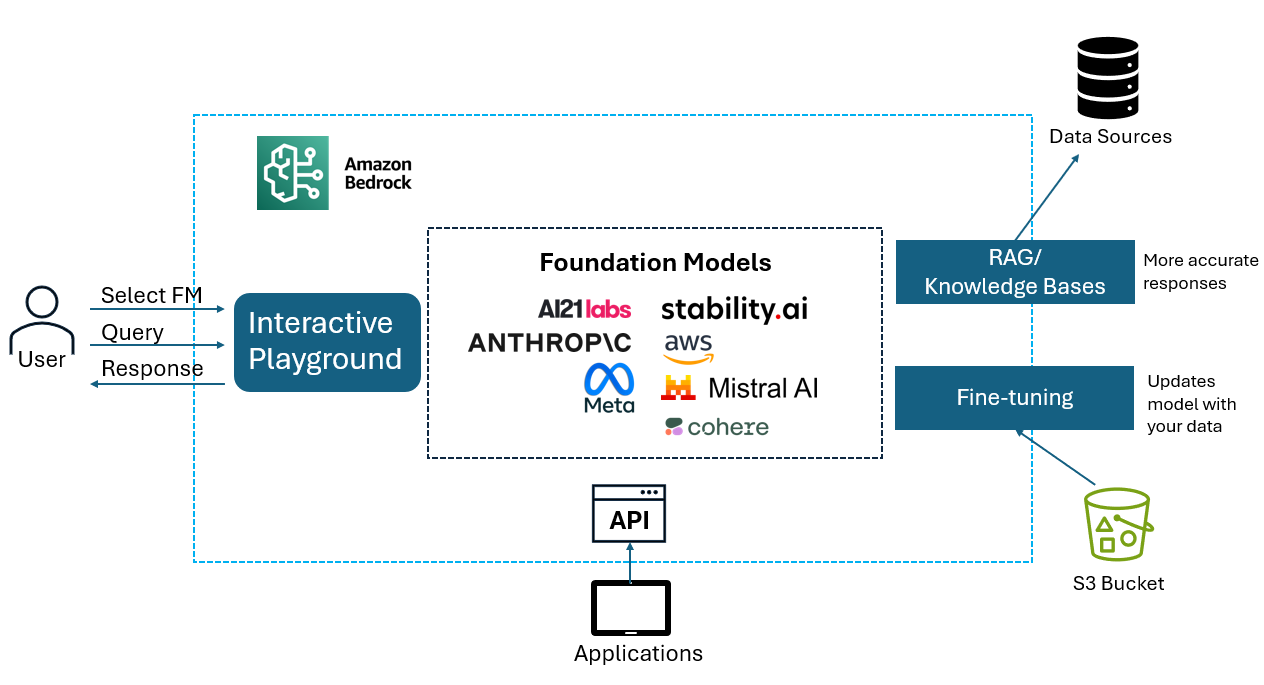
Here's how RAG works: Before the model generates a response, the system searches your documents for relevant information and stuffs that context into the prompt. The model then generates a response based on both its training AND the retrieved documents.
Amazon Bedrock Knowledge Bases makes RAG easy. You point it at your data sources (S3 buckets, web crawlers, or other connectors), and Bedrock handles the heavy lifting. It chunks your documents, generates embeddings using a model like Titan Embeddings, stores them in a vector database, and handles retrieval when queries come in.
The vector database part is important. Bedrock Knowledge Bases can use Amazon OpenSearch Serverless, Amazon Aurora, Pinecone, or Redis Enterprise Cloud as the vector store. The exam might ask which services can serve as the vector database for Knowledge Bases.
For the exam, remember this flow: Documents get chunked into smaller pieces, converted to vector embeddings, and stored in a vector database. When a user asks a question, the question gets converted to a vector, similar documents are retrieved, and those documents get added to the prompt as context. The model then generates an answer using both its training and the retrieved context.
Why does RAG matter? It reduces hallucinations because the model can cite actual documents. It keeps information current without retraining. And it lets you use foundation models with your proprietary data without fine-tuning.
Bedrock Agents: When Models Need to Take Action
Knowledge Bases answer questions, but Agents actually do things. Agents can break down complex tasks, call APIs, and interact with external systems.
Example: "Book a meeting room for tomorrow at 2pm". An agent figures out it needs to check availability, find a room, and make the reservation.
Action Groups: These define the specific actions (like API calls) the agent is allowed to take.
Pro Tip: The exam tests the concept of agents as tools for multi-step reasoning and action-taking. If a question describes a scenario where a model needs to interact with external systems or complete multi-step tasks, Agents is probably the answer.
Guardrails: Keeping Models in Their Lane
Guardrails help you set boundaries to ensure responsible AI. You can configure filters to:
Block specific denied topics.
Filter harmful content.
Redact PII (Personally Identifiable Information) like SSNs or names.
Prevent the model from giving medical advice it isn't qualified to provide.
Pro Tip: The exam loves guardrails questions because they tie into responsible AI (Domain 4). If a scenario describes concerns about inappropriate content, PII exposure, or off-topic responses, guardrails is your answer.
Fine-Tuning: When RAG Isn't Enough
Fine-tuning is going to be a big part of your exam, so let's dig in. The basic idea is that you take a copy of a foundation model and adapt it by adding your own data. When you fine-tune, you're actually changing the underlying weights of the base foundation model. This is different from RAG, where you're just adding context to prompts.
To fine-tune a model in Bedrock, you need to provide training data in a specific format, stored in Amazon S3. Bedrock does its thing, and you get a fine-tuned version of the model that incorporates your data. Here's a critical exam point: to use a fine-tuned custom model, you must use provisioned throughput, which is a different (and more expensive) pricing model than on-demand. Also, not all models can be fine-tuned. The ones that can are usually open-source models like Llama.
Instruction-Based Fine-Tuning
This is the most common type you'll see on the exam. Instruction-based fine-tuning improves the model's performance on domain-specific tasks. The key phrase to look for is "domain-specific," meaning the model gets further trained on a particular field or area of knowledge.
Here's what makes instruction-based fine-tuning unique: it uses labeled examples in the form of prompt-response pairs. You're showing the model "when someone asks X, respond with Y." For example, if the prompt is "Who is the CEO?" the completion might be "The CEO is Jane Smith, who has led the company since 2020." You're giving information but you’re also teaching the model how you want it to structure and tone its responses.
If an exam question mentions labeled data or prompt-response pairs, instruction-based fine-tuning is your answer.

Continued Pre-Training (Domain Adaptation)
This is a different beast. With continued pre-training, you're continuing the training of the foundation model using unlabeled data. Remember, foundation models were originally trained on massive amounts of unlabeled data from the internet. Continued pre-training follows the same pattern.
This is also called domain-adaptation fine-tuning because it makes the model an expert in a specific domain. Imagine feeding the entire AWS documentation to a model. You're not giving it question-answer pairs. You're just dumping raw information. The model learns the terminology, concepts, and relationships in that domain.
The exam tip here is straightforward: if the question mentions unlabeled data, the answer is continued pre-training. If it mentions labeled data or prompt-response pairs, it's instruction-based fine-tuning.
Continued pre-training is particularly useful for teaching industry-specific terminology and acronyms. Financial services, healthcare, legal documents... all of these have specialized language that base models might not handle well.

Single-Turn vs. Multi-Turn Messaging
These are subsets of instruction-based fine-tuning that deal specifically with conversational interactions.
Single-turn messaging is when you provide examples of a single exchange: what the user asks and what the assistant should reply. The training data includes a system prompt (optional context), and messages with roles (user or assistant) and content. You're fine-tuning how a chatbot should respond to individual questions.
Multi-turn messaging extends this to full conversations. You alternate between user and assistant roles across multiple exchanges. This helps the model understand how to handle conversations with bigger context, maintaining coherence across a back-and-forth dialogue.

Transfer Learning: The Bigger Picture
Transfer learning is a broader concept than fine-tuning, but it appears on the exam. Transfer learning is the idea of using a pre-trained model and adapting it to a new, related task.
For image classification, you might use a pre-trained model that already knows how to recognize edges and shapes, then adapt it to recognize specific types of images. For language models like BERT or GPT, the model already understands language structure, so you adapt it to your specific task.
Here's the exam trick: fine-tuning is actually a specific type of transfer learning. If a question doesn't mention fine-tuning specifically, but describes adapting a pre-trained model to a new task, the general answer is transfer learning.
Fine-Tuning Cost Considerations
The exam might ask about pricing, so here's what you need to know. Re-training a foundation model requires a higher budget because you're paying for computation. Instruction-based fine-tuning is usually cheaper because the computations are less intense and you typically need less data. Continued pre-training is more expensive because you need much more data and the training is more intensive.
Beyond the training costs, you also need an experienced machine learning engineer to prepare the data, perform the fine-tuning, and evaluate the resulting model. And remember, fine-tuned models require provisioned throughput, adding ongoing costs.
When to Fine-Tune: Use Cases
The exam loves to ask when fine-tuning is appropriate. Here are the scenarios where it makes sense:
You want a chatbot with a particular persona or tone, like sounding more formal for enterprise customers or more casual for consumer apps. You need the model trained on more up-to-date information than what the base model accessed during its original training. You have exclusive proprietary data like historical emails, customer service records, or internal documentation that base foundation models never saw. You need targeted capabilities like specific categorization tasks or assessing accuracy in a particular domain.
For exam questions, identify the type of data (labeled vs. unlabeled), the goal (style/tone vs. domain expertise), and the cost tolerance. Match those to the appropriate fine-tuning approach.
Fine-Tuning vs. RAG: Know the Difference
The exam will absolutely test whether you understand when to use RAG versus fine-tuning. They solve different problems, so here's how to think about it.
Use RAG when your data changes frequently. Fine-tuning bakes information into the model weights, so if your product catalog updates weekly, RAG is the better choice. RAG is also preferred when you need citations and sources (the model can point to specific documents), when you're working with large document sets, or when you want to avoid the cost and time investment of fine-tuning.
Use fine-tuning when you need to change the model's fundamental style, tone, or persona. If you want the model to sound like your brand or respond in a specific way, fine-tuning adjusts how it communicates. Fine-tuning is also the answer when you have domain-specific terminology the model handles poorly, or when RAG retrieval just isn't cutting it for your use case.
Here's a practical way to remember it: RAG adds knowledge (what the model knows), while fine-tuning changes behavior (how the model responds).
| Feature | Use RAG When... | Use Fine-Tuning When... |
|---|---|---|
| Primary Goal | You need factual accuracy and citations. | You need to change the model's style, tone, or behavior. |
| Data Frequency | Your data changes frequently. | Your data is stable and requires specialized domain knowledge. |
| Complexity | Fast and flexible setup. | Requires time and high-quality training data. |
Token Economics: Managing the Bill
Bedrock charges by the token (roughly 4 characters). Your cost is: Input Tokens (Prompt + RAG Context) + Output Tokens (Generated Response).
Different models have different pricing. Smaller, faster models cost less per token. Larger, more capable models cost more. The exam might give you a scenario and ask you to identify how to reduce costs. Common answers include using a smaller model for simpler tasks, reducing prompt length, caching common responses, and using batch processing instead of real-time inference for non-urgent work.
Pricing Models:
On-Demand: Pay-as-you-go. Great for variable workloads.
Provisioned Throughput: Dedicated capacity for high-volume, consistent performance.
Final Exam Cheat Sheet
Serverless/Managed? Think Bedrock.
Proprietary documents/hallucination reduction? Think Knowledge Bases/RAG.
Multi-step tasks/API calls? Think Agents.
PII protection/Topic restrictions? Think Guardrails.
Responses too "random"? Lower the temperature.
Amazon Bedrock is AWS's answer to the question "How do I use these amazing foundation models without becoming an ML infrastructure expert?" It gives you model choice, managed infrastructure, and powerful features like Knowledge Bases, Agents, and Guardrails.
For the exam, focus on understanding the service architecture, when to use different features, and how the pieces fit together. Bedrock questions often come down to matching the right tool to the scenario.
Coming from Microsoft, I find Bedrock conceptually similar to Azure OpenAI Service but with more model variety and tighter integration with the AWS ecosystem. If you're making the same transition I am, the concepts will feel familiar even if the service names are different.
I know this was A LOT but I really wanted to go deep on what you need to know to crush the exam. Next up in this series, we're tackling Responsible AI because Domain 4 makes up 14% of the exam and we haven't touched it yet.