

Responsible AI on AWS: The Ethics Chapter You Can't Skip
I'll be honest with you. When I first saw "Responsible AI" on the exam outline, I thought it would be the fluffy feel-good section I could skim through. Ethics lectures in tech always felt like checkbox exercises, right? Wrong. Domain 4 is 14% of your exam score, and the questions are surprisingly specific. AWS wants you to know actual tools, actual metrics, and actual strategies for building AI that doesn't go off the rails.
Coming from the Microsoft world, I'm familiar with their Responsible AI principles. AWS takes a similar approach but with its own tooling ecosystem. Here is what you actually need to know to pass this section.
The Core Dimensions of Responsible AI
The exam expects you to know the official dimensions of Responsible AI. While concepts like "inclusivity" are important, AWS uses specific terminology.
Fairness is the big one. This means your system treats all groups of stakeholders equitably. If a loan approval model approves 80% of applicants from one demographic but only 40% from another despite similar qualifications, you have a fairness violation. The exam focuses heavily on detecting this using metrics like Class Imbalance and Demographic Parity.
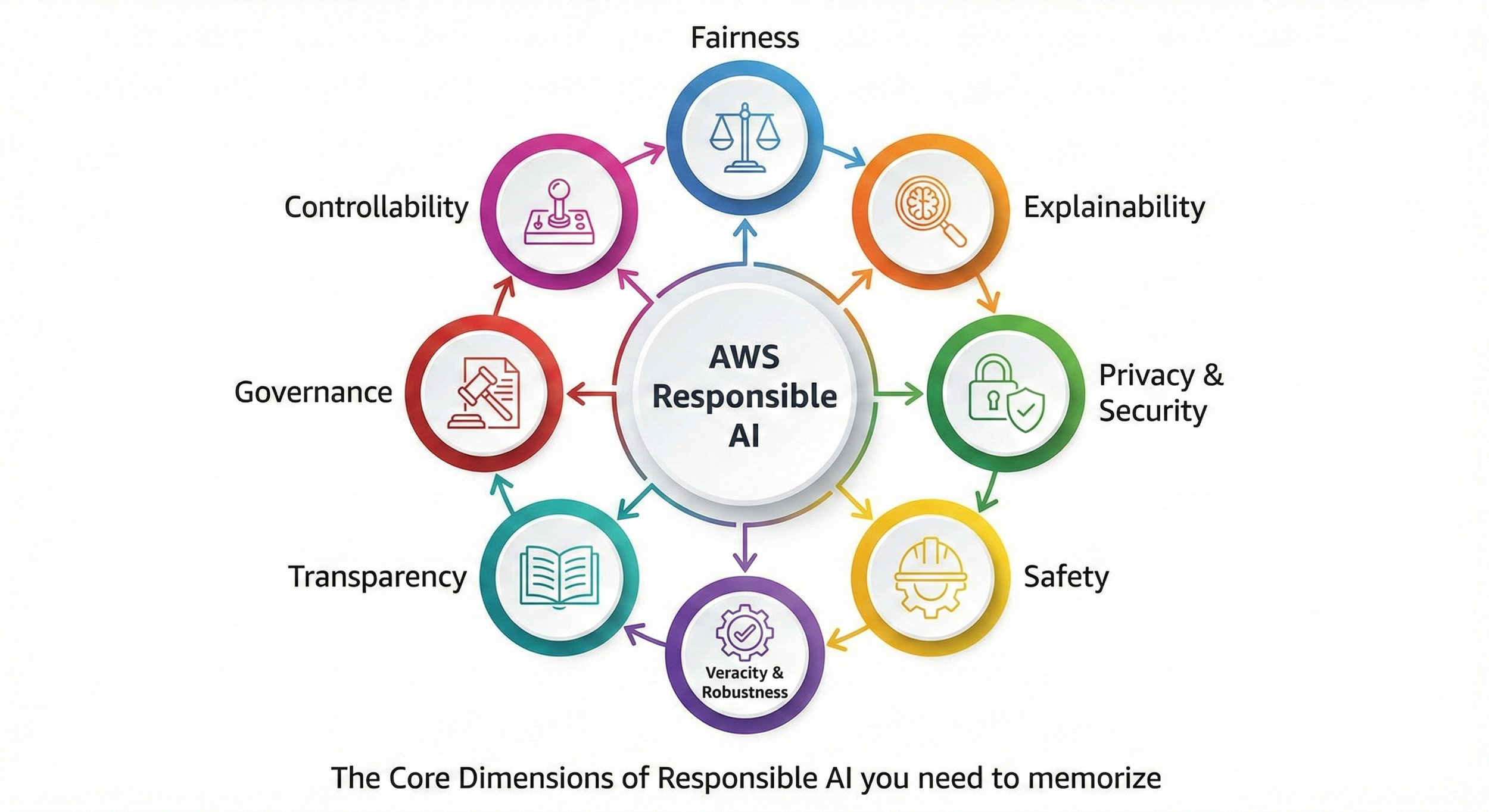
Explainability is the ability to understand and evaluate system outputs. It’s not enough for the model to be right; you need to know why it was right. This is especially critical in regulated industries like finance and healthcare where "the black box said so" isn't a legal defense.
Privacy and Security are responsible AI tenets, not just infrastructure tasks. This means data is protected throughout the lifecycle, and users have control over how their data is used (or not used) for training.
Safety is about reducing harmful system output and preventing misuse. This dimension asks whether your AI can produce dangerous, toxic, or inappropriate content and what safeguards exist to prevent that. On the exam, this connects directly to Guardrails for Amazon Bedrock, which lets you define content policies and block harmful outputs before they reach users.
Veracity and Robustness are often grouped together. Veracity means the output is truthful (not hallucinating), while Robustness means the system functions reliably even when inputs are messy, unusual, or malicious.
Transparency allows stakeholders to make informed choices. This is where Model Cards come in—providing a "nutrition label" for your model so users understand its intended use and limitations.
Governance ensures there is accountability. It’s the framework of people, processes, and policies that ensure AI is developed and deployed safely.
Controllability is the final piece of the puzzle. It means having a mechanism for human intervention. You can expect scenario questions asking you to spot where an AI system is acting up; the "responsible" answer is having a way to override the model, disengage it, or manually correct its outputs. It effectively asks: "Who is in charge, the human or the machine?"
The Legal Risks You Need to Know
The exam specifically tests legal risks associated with generative AI. Here's what AWS wants you to understand:
Intellectual property infringement is a real concern. Generative AI trained on copyrighted material risks reproducing protected content in its outputs. Companies have faced lawsuits over AI-generated code that matched copyrighted repositories. Expect scenario questions asking you to spot this risk.
Biased model outputs create legal exposure. Hiring algorithms discriminating against protected classes expose organizations to immediate regulatory action and lawsuits. The EU AI Act and various US state laws increasingly hold companies accountable for algorithmic discrimination.
Loss of customer trust might not sound like a "legal" risk, but it has serious business consequences. When AI systems fail publicly or produce harmful outputs, the reputational damage can be severe. The exam frames this as a risk to manage.
End user risk refers to harm that reaches the people interacting with your AI. A medical chatbot giving dangerous advice, a financial advisor recommending unsuitable investments, a content moderation system failing to catch harmful material. You're responsible for what your AI does.
Hallucinations deserve their own category. When LLMs generate plausible sounding but completely false information, users might act on it. Imagine a legal research AI citing fake court cases (this has happened) or a medical AI inventing drug interactions. The exam tests whether you understand this as a specific, manageable risk.
Dataset Characteristics: Garbage In, Garbage Out
One of the most testable concepts in Domain 4 is understanding what makes a good training dataset. The exam presents scenarios and asks you to identify dataset problems.
Diversity means your dataset represents the full range of inputs your model will encounter. Training a sentiment analysis model only on product reviews won't prepare it for analyzing social media posts, legal documents, or customer service transcripts.
Inclusivity in datasets means all demographic groups are adequately represented. Datasets underrepresenting specific populations inevitably lead to worse model performance for those groups. This is a measurable, testable phenomenon.
Balanced datasets have roughly equal representation across classes. Imagine training a fraud detection model where 99.9% of examples are legitimate transactions. The model simply learns that 'predicting legitimate' is the safest bet and fails to spot actual fraud.
Curated data sources matter because quality varies wildly. Web-scraped data includes errors, outdated information, and intentional misinformation. Enterprise datasets might encode historical biases. The exam wants you to understand that dataset quality directly impacts model quality.
A Note on Privacy-Preserving AI
While we cover security in Domain 5, the exam treats privacy as a Responsible AI issue, too. You should recognize two key terms that solve the "using data without exposing secrets" problem:
Differential Privacy: This technique adds statistical "noise" to a dataset. It allows a model to learn general patterns (like "people in this age group buy these shoes") without being able to memorize or reveal the data of any single individual.
Federated Learning: Instead of sending all your user data to a central server to train a model (which is a privacy risk), you send the model to the users' devices. The model learns locally on the phone or laptop and sends only the learnings (not the data) back to the central server.
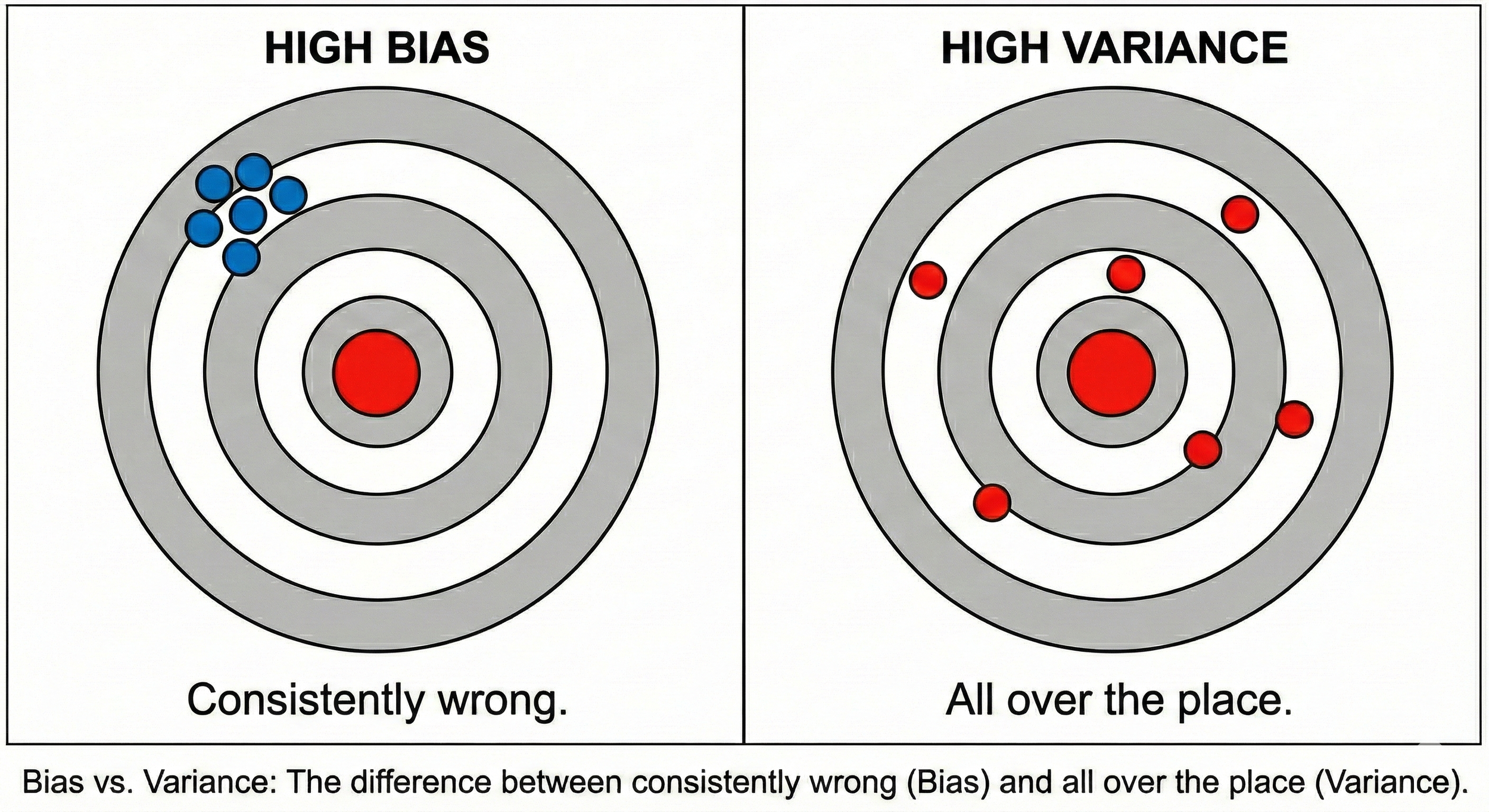
Understanding Bias and Variance
These concepts appear throughout the ML domains, but they're especially relevant to responsible AI.
Bias in the statistical sense refers to systematic errors. A biased model consistently gets things wrong in a particular direction. High bias often indicates underfitting, where the model is too simple to capture the patterns in your data.
Variance refers to how much your model's predictions change with different training data. High variance indicates overfitting, where the model memorized the training data instead of learning generalizable patterns.
The responsible AI angle is understanding how bias affects different demographic groups. A model showing high bias for one group but low bias for another creates a fairness problem, regardless of how good the overall accuracy looks. Aggregate metrics can hide disparities.
Underfitting happens when your model is too simple. It performs poorly on both training and test data because it can't capture the underlying patterns.
Overfitting happens when your model is too complex. It performs great on training data but poorly on new data because it learned noise instead of signal.
For responsible AI, overfitting to a non-representative dataset is particularly dangerous. The model learns spurious correlations that might encode bias, then fails when deployed on real-world data that looks different from training.
AWS Tools for Responsible AI
Here's where it gets practical. The exam tests specific AWS services, and you need to know what each one does.
Amazon SageMaker Clarify
This is the big one for responsible AI. SageMaker Clarify helps you detect bias in your data and models, plus it provides explainability for model predictions.
For bias detection, Clarify can analyze your dataset before training to identify imbalances. It measures things like Class Imbalance (CI), which checks if one group is underrepresented, and Difference in Proportions of Labels (DPL), which checks if positive outcomes are distributed differently across groups.
After training, Clarify can analyze your model's predictions across different groups. It calculates metrics like Demographic Parity Difference (whether different groups receive positive predictions at similar rates) and Equalized Odds Difference (whether true positive and false positive rates are similar across groups).
For explainability, Clarify uses SHAP (SHapley Additive exPlanations) values to show which features most influenced each prediction. This matters for regulated industries where you need to explain why a loan was denied or why a claim was flagged.
Exam Tip: Look for keywords like 'detect bias,' 'explain predictions,' 'feature importance,' or 'model transparency.' These almost always point to Clarify as the answer.
Amazon SageMaker Model Monitor
Model Monitor tracks your deployed models over time. Models can degrade as the real-world changes, a phenomenon called model drift. What worked six months ago might not work today.
Model Monitor checks for data drift (are inputs changing?), model drift (are predictions changing?), bias drift (is fairness degrading?), and feature attribution drift (are the important features changing?). Exceeding any of these thresholds triggers a Model Monitor alert.
For responsible AI, the bias drift detection is key. A model might be fair at deployment but become unfair over time as population distributions shift. Model Monitor catches this before it becomes a problem.
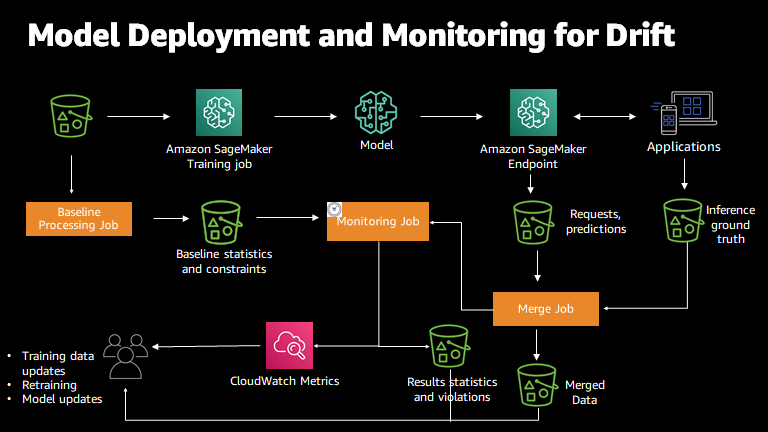
Data and model quality monitoring with Amazon SageMaker Model Monitor - Amazon SageMaker AI https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html
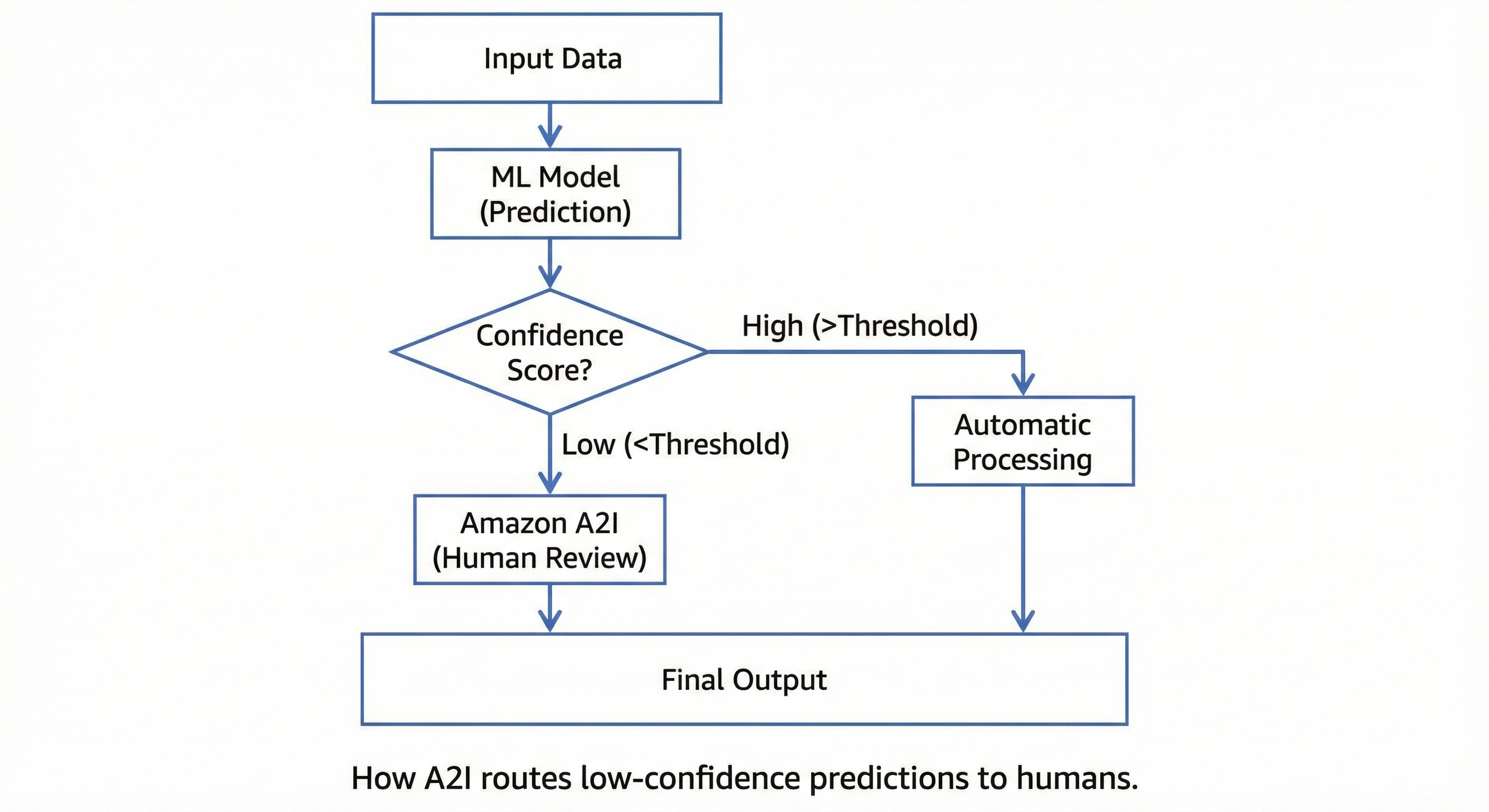
Amazon Augmented AI (Amazon A2I)
A2I implements human-in-the-loop workflows. Not every prediction should be fully automated. For high-stakes decisions or low-confidence predictions, you want a human to review.
A2I integrates with other AWS AI services. You define conditions that trigger human review (confidence below a threshold, certain prediction types, random sampling for quality assurance), and A2I routes those cases to human reviewers through a managed workflow.
Exam Tip: The exam tests A2I as the answer when questions mention "human review," "human oversight," "low confidence predictions," or "regulatory requirements for human involvement."
Guardrails for Amazon Bedrock
We covered Guardrails in the Bedrock post, but they're also a responsible AI tool. Guardrails let you define content policies, filter harmful outputs, redact PII, and block specific topics.
For responsible AI, Guardrails help you prevent your generative AI from producing harmful, biased, or inappropriate content. You're not just hoping the model behaves; you're enforcing boundaries.
Invisible Watermarking (Amazon Titan Image Generator)
While Guardrails filter what comes in and out, you also need to track what happens to generated content after it leaves your system. This touches on the Veracity principle.
Exam Tip: When asked how to identify AI-generated images to prevent misinformation or IP disputes. The answer is usually Amazon Titan Image Generator. It automatically embeds an invisible watermark into every image it creates. Unlike a visible logo, this watermark persists even if the image is cropped, resized, or compressed, giving you a reliable mechanism for transparency and detection.
Amazon Q Developer (Reference Tracker)
Speaking of IP risks, remember that bit about lawsuits over stolen code? AWS has a specific feature for that, too.
If you're using Amazon Q Developer (formerly CodeWhisperer) for coding assistance, it has a built-in Reference Tracker. If the AI suggests code that looks like public open-source code, it flags it and tells you the license type.
Exam Tip: If a question asks about "preventing use of code with specific licenses" or "detecting if AI code resembles open source," the answer is the Reference Tracker in Amazon Q Developer.
SageMaker Model Cards
Model Cards are documentation templates that capture important information about your model. They're AWS's implementation of a broader industry practice for model transparency.
A Model Card includes intended uses (what the model is designed for), limitations (where it shouldn't be used), training data description, evaluation metrics, ethical considerations, and deployment information.
Model Cards support transparency because they give stakeholders visibility into what a model does and doesn't do. Regulators, auditors, and users can review the card to understand the model's scope and limitations.
Exam Tip: The exam can be referring to Model Cards when questions mention "documentation," "transparency," "model information," or "communicating model limitations."
Transparency vs. Explainability
The exam distinguishes between these concepts, so know the difference.
Transparency is about openness regarding how a model works. A transparent model lets you inspect its architecture, training data, and decision process. Open source models with published training methodologies are more transparent than proprietary black boxes.
Explainability is about understanding why a model made a specific prediction. Even if a model's inner workings are proprietary (not transparent), you might still be able to explain individual predictions using techniques like SHAP values.
Some models are inherently more explainable than others. Decision trees are highly explainable because you can trace the path from input to output. Deep neural networks are less inherently explainable because the reasoning is distributed across millions of parameters.
The tradeoff question comes up on the exam. More complex models (deep learning) often achieve better performance but are harder to explain. Simpler models (linear regression, decision trees) are easier to explain but might miss complex patterns. Choosing the right model involves balancing accuracy against explainability requirements.
Regulated industries like healthcare and finance often require explainability. You can't just tell a patient "the AI said so." You need to explain which factors contributed to a diagnosis or treatment recommendation.
Human-Centered Design for AI
This is a conceptual area the exam touches on. Human-centered design means building AI systems that work well for the humans who use them.
Key principles include designing for human oversight (humans should be able to review, override, and correct AI decisions), providing appropriate transparency (users should understand when they're interacting with AI and how it works at a level appropriate to their role), enabling feedback loops (users should be able to report problems and that feedback should improve the system), and considering the full range of users (your system should be accessible and usable by people with different abilities, backgrounds, and technical sophistication).
Exam Tip: The exam might present scenarios where human oversight is inadequate and ask you to identify the problem or recommend improvements.
Responsible Model Selection
One exam topic that surprised me was environmental considerations for model selection. Training large models consumes significant energy. The carbon footprint of training a single large language model can exceed the lifetime emissions of several cars.
Responsible model selection considers whether you need the largest model or whether a smaller, more efficient model would serve your use case adequately. Using pre-trained models instead of training from scratch reduces environmental impact. Choosing efficient inference options (smaller models, quantization, efficient hardware) reduces ongoing energy consumption.
AWS frames this as part of responsible AI because environmental sustainability is an ethical consideration. Don't expect deep questions on this, but know that it's a factor in responsible model selection.
Practical Exam Tips for Domain 4
How to Spot the Right Answer After doing hundreds of practice questions, I’ve noticed clear patterns in how AWS phrases things in Domain 4.
Bias Detection = Clarify. If the scenario involves detecting imbalances in training data or checking if a model is favoring one group over another, SageMaker Clarify is almost always your answer.
"Why did it do that?" = SHAP. Any mention of feature importance or explaining a specific prediction points to SHAP values (also part of Clarify).
Drift = Model Monitor. If the question describes a model that was working fine but is now performing poorly due to changing real-world data, you are looking at model drift. SageMaker Model Monitor is the tool that catches this.
The "Human" Element = A2I. AWS loves scenarios where a model has low confidence. The solution is never "retrain immediately"—it’s "send to Amazon A2I for human review."
Licensing & IP = Q Developer. If you see a question about coding assistants and open-source license violations, look for the Reference Tracker in Amazon Q Developer.
Fakes & Watermarks = Titan. For preventing misinformation or identifying AI-generated images, the invisible watermark feature in Amazon Titan is the standard answer.
Wrapping Up
Responsible AI isn't just about being ethical (though that matters). It's about building AI systems that work reliably, fairly, and transparently. The AWS AI Practitioner exam tests whether you understand the risks of irresponsible AI and the tools available to mitigate those risks.
The good news is that AWS provides concrete services for each responsible AI challenge. You don't have to build bias detection from scratch; you use Clarify. You don't have to manually route predictions for human review; you use A2I. Knowing which tool solves which problem is what the exam tests.
Next up in this series, we're tackling Domain 5: Security, Compliance, and Governance. That's another 14% of the exam, covering IAM for AI, data encryption, compliance frameworks, and audit trails. Combined with this Responsible AI post, you'll have the full 28% from Domains 4 and 5 covered.