

From Cloud-Agnostic to AI-Sovereign: Architecting Your Private AI Factory with AWS
Let's be honest: for the past decade, "cloud-agnostic" was the polite fiction we told ourselves while still writing CloudFormation templates at 2 AM. But here's the thing—cloud-agnostic was always about hedging bets on commodity compute. It was never designed for the world we're living in now, where the real strategic asset isn't where your VMs run, but where your AI models train.
If you're an architect in a regulated industry—finance, healthcare, government, defense—you've likely spent the last two years watching the AI revolution from the sidelines. Not because you lack vision, but because you have a CISO, a compliance team, and data residency requirements that make "just spin it up in us-east-1" a career-limiting suggestion.
At AWS re:Invent 2025, Amazon announced something that changes this equation: AWS AI Factories. And no, this isn't another Outposts rebrand with a fresh coat of marketing paint. This is AWS acknowledging that the future of enterprise AI isn't about moving your data to the cloud—it's about moving the cloud to your data.
What Is an AWS AI Factory, Actually?
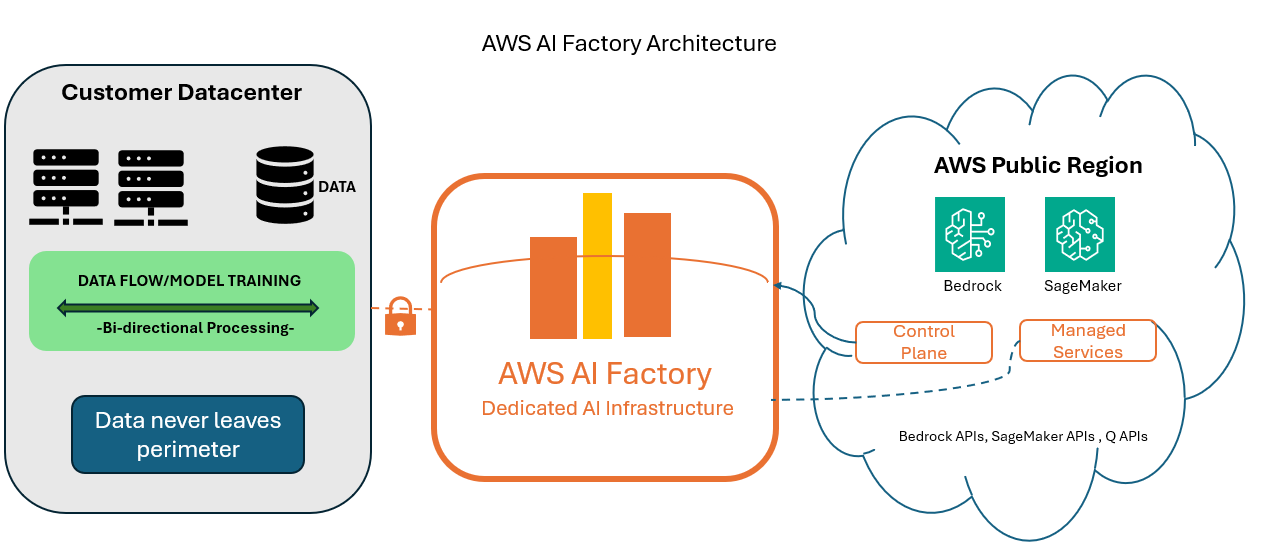
Strip away the keynote theater, and here's what you're getting: dedicated, AWS-managed AI infrastructure deployed inside your data center. You provide the real estate and power. AWS deploys the hardware, networking, storage, and services—then operates it as a private AWS Region exclusively for your organization.
This isn't "here's a rack of GPUs, good luck with the firmware." AWS AI Factories include the full stack: Trainium3 UltraServers (AWS's new 3nm AI accelerators delivering 362 FP8 petaflops per system), NVIDIA Grace Blackwell GPUs, petabit-scale Elastic Fabric Adapter networking, high-performance storage via FSx for Lustre, and—critically—the managed services layer: Amazon Bedrock and SageMaker AI.
The architectural significance: your data never leaves your facility. Your models train on your hardware, in your building, behind your firewall. But you get cloud-scale AI infrastructure without spending three years negotiating with NVIDIA, building out cooling systems, and hiring a team of kernel engineers to tune your collective communications.
The Sovereignty Bridge: Why This Isn't Cloud Avoidance
Let me address the elephant in the room: "Isn't this just on-prem with extra steps?"
No. And here's the architectural distinction that matters.
Traditional on-prem AI means you're responsible for everything: hardware procurement (enjoy those 18-month GPU lead times), integration, networking topology, storage tiering, driver compatibility, and the ongoing operational burden of keeping frontier-scale infrastructure running. Most enterprises that attempt this end up with expensive rack art and a team of engineers who've memorized NVIDIA's CUDA documentation.
AWS AI Factories flip the operational model. AWS handles the undifferentiated heavy lifting—procurement, integration, lifecycle management, firmware updates, and hardware failure remediation. You focus on what actually matters: training models on your proprietary data and deploying AI applications that move your business forward.
This is AI sovereignty, not cloud avoidance. You're not retreating from modern infrastructure patterns—you're extending them into environments where public cloud egress was never an option.
The Infrastructure Abstraction: Eliminating Years of Pain
If you've ever tried to build AI training infrastructure from scratch, you know the procurement timeline alone can kill a project. GPU allocations that slip by quarters. Networking gear that arrives before the compute it's supposed to connect. Storage systems that technically meet the specs but create bottlenecks at scale. And let's not forget the joy of firmware compatibility matrices that read like ancient prophecies.
AWS AI Factories collapse this timeline dramatically. Here's what AWS is handling:
Compute: Trainium3 UltraServers scale up to 144 chips per system, delivering 4.4x more performance than the previous generation with 40% better energy efficiency. For organizations requiring NVIDIA silicon, the factories support GB300 and upcoming Vera Rubin architectures.
Networking: The NeuronSwitch-v1 fabric doubles inter-chip interconnect bandwidth versus Trainium2. At cluster scale, EC2 UltraClusters 3.0 can connect up to one million Trainium chips—the same infrastructure powering Project Rainier, Anthropic's training cluster with over 500,000 Trainium2 chips.
Storage: High-performance storage layers designed for the throughput demands of large-scale training, with the same FSx for Lustre integration available in public regions.
Lifecycle management: AWS handles hardware failures, firmware updates, and capacity planning. When Trainium4 ships (with its 3x FP8 performance improvement and NVLink Fusion support), your infrastructure upgrades without you rebuilding your architecture.

The Integrated AI Stack: It's Not Just Hardware
Here's where AI Factories diverge from "we'll ship you servers" approaches. The value proposition isn't just silicon—it's the complete AWS AI services layer running in your facility.
Amazon Bedrock: Access to foundation models from Anthropic, Meta, Mistral, and Amazon's own Nova family—without negotiating separate contracts or sending inference requests to public endpoints. For regulated workloads, this is transformative: you get model access without data egress.
Amazon SageMaker AI: The full training and deployment platform, running locally. Build custom models, fine-tune foundation models on your proprietary data, and deploy inference endpoints—all within your data center boundary.
Nova Forge: Perhaps the most interesting addition. Nova Forge lets you build custom "Novellas"—frontier model variants trained on your proprietary data. Unlike standard fine-tuning, you get access to pre-trained, mid-trained, and post-trained model checkpoints, allowing you to inject domain knowledge earlier in the training pipeline without catastrophic forgetting of base capabilities. Reddit and Sony are already using this for content moderation and review automation respectively.

Architectural Positioning: Where AI Factories Fit
If you're already running AWS Outposts or operating in a Dedicated Region, you're probably wondering how AI Factories relate to your existing architecture. Here's the whiteboard version:
AWS Outposts: General-purpose compute extension. Good for latency-sensitive workloads, data residency for standard applications, and hybrid architectures where you need local compute with cloud management. Not optimized for large-scale AI training.
Dedicated Regions / Sovereign Clouds: Full AWS Region deployments for government and highly regulated customers. Comprehensive service availability, but still fundamentally a shared infrastructure model within the dedicated boundary.
AI Factories: Purpose-built for frontier AI workloads. Exclusive infrastructure for a single customer or designated community. Designed for massive-scale training (think hundreds of thousands of accelerators), agentic workloads, and the inference demands of deploying custom foundation models. This is where you run your coding agents, your security automation, and your domain-specific reasoning systems.

AWS is already deploying AI Factories at scale. HUMAIN, backed by Saudi Arabia's Public Investment Fund, is building an "AI Zone" with up to 150,000 chips—a mix of NVIDIA GB300s and Trainium accelerators—powered entirely by AI Factory infrastructure. This isn't a pilot program; it's production-scale deployment.
Why This Resonates: The Real Tension Points
If you've been blocked on AI initiatives by compliance, AI Factories address the core tensions directly:
Innovation speed vs. compliance: You no longer have to choose between cutting-edge AI capabilities and regulatory adherence. The infrastructure is inside your perimeter, operated to AWS standards, with the same security certifications across classification levels from Unclassified through Top Secret.
Frontier AI vs. risk management: Access to the latest accelerators and model architectures without the operational risk of building and maintaining frontier infrastructure yourself. AWS's track record with Project Rainier—deploying 500,000 Trainium2 chips in under a year—demonstrates execution capability most enterprises can't match internally.
Custom models vs. data gravity: Your proprietary data stays where it is. Models come to the data, not the other way around. With Nova Forge, you can build truly differentiated AI systems trained on your institutional knowledge without ever moving that knowledge outside your control.
Developer experience vs. sovereignty requirements: Your engineers get the same APIs, the same SageMaker workflows, the same Bedrock integration patterns they'd use in public cloud. Sovereignty doesn't mean regression to 2015-era deployment models.
The Long View: AI Factories as Enterprise Pattern
AWS AI Factories represent a strategic acknowledgment: the next wave of enterprise AI will be built by organizations that can train and deploy models on their most sensitive data. Public cloud will continue to dominate commodity workloads and less-regulated use cases. But for the highest-value AI applications—those built on proprietary institutional knowledge—the infrastructure needs to go to the data.
This isn't a retreat from cloud architecture. It's an extension of cloud operating models into environments that were previously unreachable. The patterns you've learned—infrastructure as code, managed services, API-driven deployment—they all transfer. The constraint of "data must leave your building" does not.
For architects in regulated industries, this is the on-ramp you've been waiting for. The question is no longer "can we do frontier AI?" It's "what do we build first?"
Welcome to the age of AI sovereignty. Your data center just got a lot more interesting.