

Generative AI Unleashed: Foundation Models, LLMs, and the Tech Behind the AI Revolution
Welcome back to our AWS AI Practitioner journey! After diving deep into neural networks, it's time to explore the technology that's captured the world's imagination: Generative AI. If you've used ChatGPT, created images with DALL-E, or wondered how Amazon Bedrock works, this post is for you.
Coming from Microsoft Azure, I remember when Chat-GPT first started making waves. Now, as I explore AWS's approach with Amazon Bedrock and Titan models, I'm seeing how the generative AI landscape has evolved into something truly remarkable. Let's demystify these technologies together!
What Makes Generative AI Different?
Remember our animal classification model from earlier posts? Traditional AI excels at recognizing patterns and making predictions: "This is a cat with 95% confidence." Generative AI flips the script entirely. Instead of just identifying what exists, it creates something new.
Think of it this way: Traditional AI is like a master art critic who can identify every painting style and artist. Generative AI is the artist who can paint original masterpieces in any style you request. It doesn't just understand - it creates.
The key insight? Generative AI is a subset of deep learning that generates new data similar to what it was trained on. Whether that's writing a poem, creating an image of a "cartoon dog wearing a spacesuit," or generating code that actually works, these models combine learned patterns in novel ways.
![Placeholder: Visual showing Traditional AI (input → classification) vs Generative AI (prompt → creation), with examples]
Foundation Models: The Powerhouses Behind Gen AI
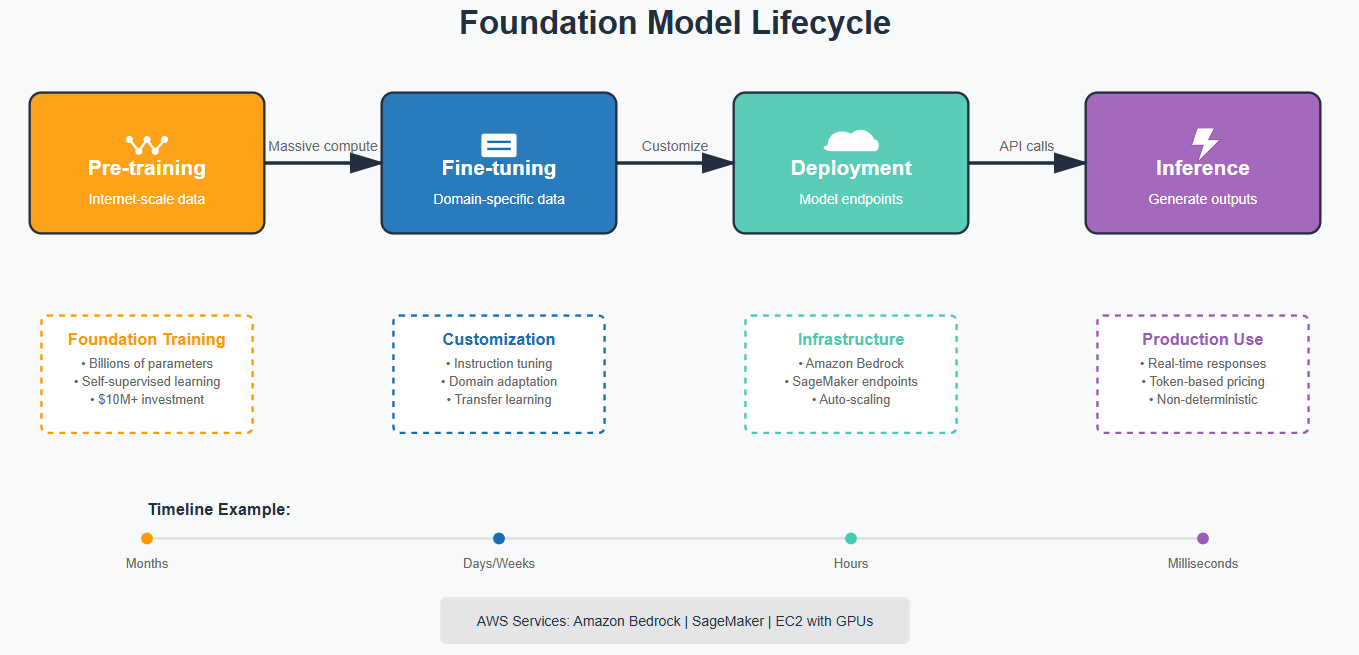
Here's where things get interesting - and expensive. Foundation Models (FMs) are massive neural networks pre-trained on internet-scale data. We're talking about models that cost tens of millions of dollars to train, requiring resources that make traditional ML look like a calculator compared to a supercomputer.
Why Foundation Models Changed Everything
In the old world (like, 2020), you'd need to:
Gather labeled data for each specific task
Train a separate model for each use case
Maintain multiple models in production
Pray your models don't drift too much
With Foundation Models, you:
Start with a pre-trained model that already understands language, images, or both
Adapt it to multiple tasks without retraining from scratch
Use techniques like prompt engineering to guide behavior
Deploy one model for dozens of use cases
The economics are compelling. Instead of every company training their own language model from scratch (impossible for 99% of organizations), we can all leverage models from companies like Anthropic, OpenAI, Meta, and Amazon who've already invested those millions.
Large Language Models: The Text Wizards
LLMs are the rock stars of the generative AI world. These transformer-based models understand and generate human-like text by learning patterns from vast amounts of internet text, books, and articles. But here's the fascinating part - they don't "understand" language the way we do.
How LLMs Actually Work
LLMs break down text into tokens (think of them as chunks of meaning - could be words, parts of words, or even punctuation). Each token gets converted into embeddings - numerical representations that capture meaning and relationships. These embeddings exist in a high-dimensional space where similar concepts cluster together.
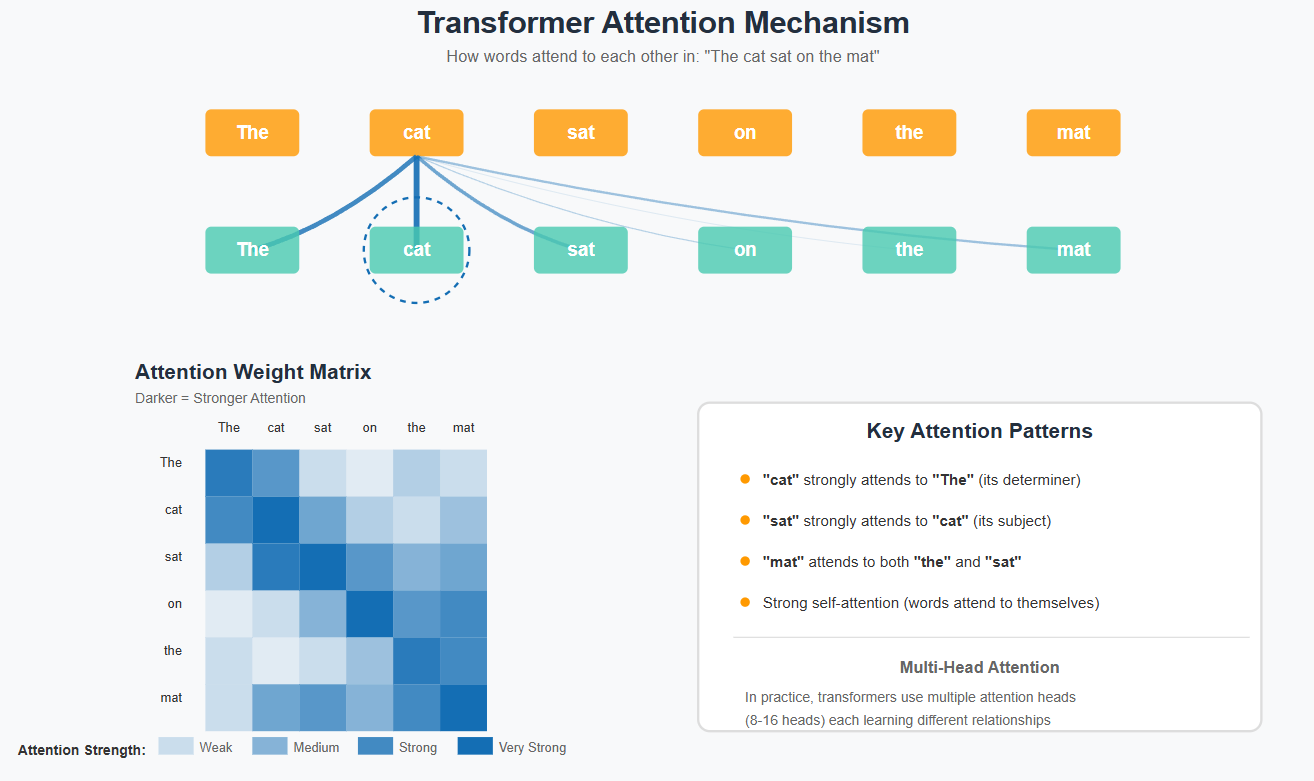
When you give an LLM a prompt like "After the rain, the streets were," it doesn't deterministically complete the sentence. Instead, it:
Calculates probabilities for thousands of possible next words
Considers context from transformer attention mechanisms
Samples from these probabilities (which is why the same prompt can generate different outputs)
Continues this process token by token
This probabilistic nature is why ChatGPT might say the streets were "flooded" one time and "glistening" another. It's not being inconsistent - it's sampling from a probability distribution, just like rolling weighted dice.
The Transformer Revolution
Transformers changed everything by processing sequences in parallel rather than sequentially. While older models would read text word-by-word like a human, transformers see the entire context at once, understanding relationships between all words simultaneously. This "attention mechanism" lets them capture long-range dependencies - understanding that a pronoun in paragraph 10 refers to a character introduced in paragraph 1.
Diffusion Models: From Noise to Art
While LLMs dominate text, diffusion models rule the visual realm. These models work through an almost magical process:
Forward Diffusion: Order to Chaos
The model learns by taking clear images and gradually adding noise until they become pure static. It's like watching a photograph slowly dissolve into TV static, step by careful step.
Reverse Diffusion: Chaos to Order
Once trained, the model reverses the process. Starting with pure noise, it gradually removes randomness, sculpting meaningful images from chaos. It's learned the statistical patterns that distinguish "dog" from "cat" from "waterfall," and can reconstruct these patterns from nothing.
This is how Stable Diffusion, DALL-E, and Amazon's Titan Image Generator create images that never existed before. They're not copying or combining existing images - they're reconstructing patterns learned from millions of examples, creating genuinely novel outputs.
Multimodal Models: The Swiss Army Knives
The latest frontier in generative AI transcends the boundaries between different types of data. Multimodal models don't just process text or images in isolation - they understand multiple modalities simultaneously, creating a unified understanding across different forms of information. Instead of relying on a single type of input or output, these models can process and generate multiple modes of data at once. A multimodal model could take in an image along with text instructions and generate a new image with a caption describing it, or analyze a video while understanding its audio track and any embedded text.
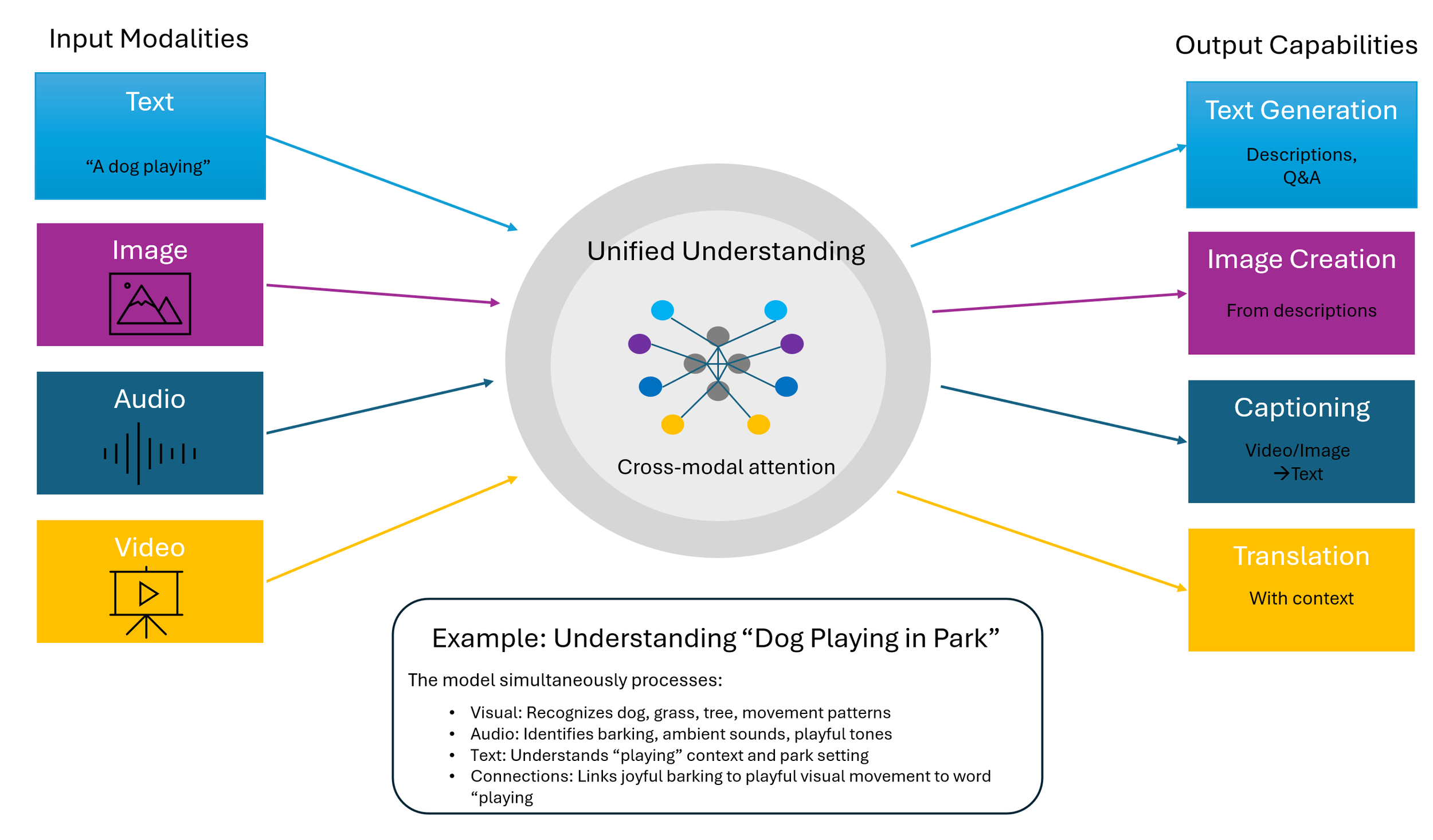
Multimodal Models: Understanding Across Modalities
How models process and connect different types of data simultaneously
These models have learned how different modalities like images, text, and audio are fundamentally connected and influence each other. They understand that the word "dog" isn't just a sequence of letters but relates to specific visual patterns of fur and four legs, the sound of barking, particular movement patterns, and even emotional associations. This deep, interconnected understanding enables remarkable capabilities: answering complex questions about images by combining visual and textual reasoning, creating graphics from detailed text instructions while maintaining consistency, automating video captioning that captures both visual and audio elements, and even translating content while preserving relevant visual context. The true power lies not in processing multiple inputs, but in understanding the relationships between them - how a gesture in a video relates to spoken words, or how text descriptions map to visual compositions.
Amazon Bedrock: AWS's Generative AI Platform
Now let's talk about how AWS democratizes access to these powerful models through Amazon Bedrock. As someone who's worked with Azure's OpenAI offerings, Bedrock takes a refreshingly different approach.
The Bedrock Advantage
Multi-Model Marketplace: Instead of locking you into one provider, Bedrock offers models from:
Anthropic (Claude series - great for long context)
AI21 Labs (Jurassic models)
Stability AI (Stable Diffusion)
Meta (Llama models)
Amazon (Titan models for text and images)
Cohere and Mistral AI
Your Data Stays Yours: When you use Bedrock, Amazon creates a private copy of the foundation model just for you. Your prompts and responses aren't used to train the base models. Coming from the enterprise world, this privacy guarantee is crucial.
Flexible Customization Options:
Prompt Engineering: Guide model behavior without any training
Fine-tuning: Adapt models with your labeled data (instruction-based)
Continued Pre-training: Extend models with your unlabeled domain data
RAG (Retrieval Augmented Generation): Connect models to your knowledge bases
Amazon Titan: AWS's Home-Grown Models
While you can use models from various providers, Amazon Titan deserves special attention for the exam. These models are:
Built and optimized by AWS
Available for both text and image generation
Designed for customization with your data
Integrated deeply with other AWS services
Often more cost-effective for high-volume use cases
Optimizing Model Outputs: The Art and Science
Getting great results from generative AI isn't just about choosing the right model - it's about optimizing how you interact with it.
Prompt Engineering: Your First Line of Defense
Think of prompts as instructions to a brilliant but very literal assistant. The key elements:
Instructions: Clear task description
Context: Background information to guide the model
Input Data: The specific content to process
Output Format: How you want the response structured
Example prompt that works:
You are an experienced cloud architect specializing in AWS migrations. Context: A retail company wants to move from on-premises to cloud. Task: Create a high-level migration plan focusing on data security. Format: Bullet points with timeline estimates.

Fine-Tuning: Teaching New Tricks
When prompt engineering isn't enough, fine-tuning lets you adapt models to your specific needs:
Instruction Fine-tuning (Labeled Data):
Best for: Teaching specific response formats
Example: Training a model to respond to customer service queries in your company's tone
Cost: Lower computational requirements
Data needed: Prompt-response pairs showing desired behavior
Continued Pre-training (Unlabeled Data):
Best for: Adding domain expertise
Example: Feeding all AWS documentation to make a model an AWS expert
Cost: Higher computational requirements
Data needed: Large amounts of domain-specific text
Remember: Fine-tuning changes the model's weights, creating a custom version that requires provisioned throughput in Bedrock (not on-demand pricing).
RAG: Keeping Models Current
RAG solves the knowledge cutoff problem elegantly. Instead of retraining models with new information, RAG:
Retrieves relevant documents from your knowledge base
Provides them as context to the model
Generates responses based on this fresh information
This is how Booking.com's AI Trip Planner stays current with hotel availability, or how customer service bots access the latest product information.
Real-World Magic: Use Cases That Matter
Let me share some powerful applications that show why this technology matters:
MasterCard: Improved fraud detection by 20% by using LLMs to analyze transaction patterns in context. The model predicts if a transaction location makes sense based on customer history.
Pinterest Lens: Uses multimodal models to let users photograph objects and instantly find similar items for sale. The model understands both visual and textual product descriptions.
AWS Customer: A financial services firm uses Bedrock to generate personalized investment summaries, combining market data (RAG) with client preferences (fine-tuning) to create reports that previously took analysts hours to write.
Challenges and Considerations
Let's be real about the challenges you'll face when working with generative AI. The non-deterministic nature of these models means the same prompt can generate different responses each time you run it. While this creativity is often valuable - you wouldn't want a creative writing assistant that always produces identical stories - it can complicate testing and compliance scenarios where consistency matters. You'll need to design your applications with this variability in mind, perhaps implementing voting mechanisms across multiple generations or setting temperature parameters lower for more consistent outputs.
Hallucinations present another significant challenge that every practitioner must account for. Models can generate plausible sounding but entirely incorrect information with complete confidence. They might cite non-existent research papers, invent historical facts, or create fictional product features that sound entirely reasonable. This isn't a bug to be fixed but a fundamental characteristic of how these probabilistic models work. Always implement verification layers for critical applications, whether that's human review, cross-referencing with authoritative sources, or using separate fact-checking models.
Cost at scale often catches teams by surprise. While individual API calls might cost mere fractions of a cent, these expenses compound rapidly in production. A chatbot serving thousands of users can rack up significant bills, especially if conversations involve long context windows or multiple model calls per interaction. Smart caching strategies become essential - storing common responses, implementing semantic similarity matching to avoid redundant calls, and carefully managing context window sizes. Consider that fine-tuned models require provisioned throughput in Bedrock, adding fixed monthly costs regardless of usage.
Latency remains a practical constraint that shapes architecture decisions. Large models take time to generate responses - sometimes several seconds for complex prompts. This delay might be acceptable for content generation but problematic for real-time applications. Streaming responses can improve perceived performance, breaking long outputs into chunks that appear progressively. Smaller models often provide the sweet spot between capability and speed, and you might need different models for different parts of your application - a small, fast model for initial routing and a larger model for complex reasoning tasks.
Key Take Aways
Non-Deterministic Outputs: The same prompt can generate different responses. This creativity is a feature, not a bug, but it can complicate testing and compliance.
Hallucinations: Models can generate plausible sounding but incorrect information. Always implement verification for critical applications.
Cost at Scale: While individual API calls seem cheap, costs can explode with high-volume applications. Monitor usage carefully and implement caching where possible.
Latency: Large models take time to generate responses. Consider streaming responses or using smaller models for time-sensitive applications.
Practical Tips for Getting Started
Start with Bedrock Playground: Before writing code, experiment with different models in the Bedrock console. Try the same prompt across different models to understand their strengths.
Choose the Right Model Size:
Smaller models (7B-13B parameters): Faster, cheaper, good for straightforward tasks
Larger models (70B+ parameters): Better reasoning, more nuanced outputs, higher costs
Implement Graceful Fallbacks: Always have a plan B when models don't respond as expected. This might mean trying a different model or falling back to traditional logic.
Version Your Prompts: Treat prompts as code. Version them, test them, and roll them back if needed.
Monitor Everything: Track token usage, latency, error rates, and user satisfaction. The insights will guide optimization efforts.
Key Takeaways for the Exam
Foundation Models are pre-trained on massive datasets and can be adapted for multiple tasks
LLMs use transformer architecture and process text probabilistically (non-deterministic)
Diffusion models create images by learning to reverse the process of adding noise
Amazon Bedrock provides access to multiple foundation models with privacy guarantees
Fine-tuning requires labeled data for instruction-based or unlabeled for continued pre-training
RAG provides current information without retraining models
Amazon Titan is AWS's native foundation model family
Models require provisioned throughput for fine-tuned versions, not on-demand pricing
What's Next?
In our next post, we'll dive deep into AWS AI Services - the pre-built, task-specific services like Rekognition, Comprehend, and Transcribe. We'll explore when to use these specialized services versus foundation models, and how to combine them for powerful solutions.
Resources for Deeper Exploration:
"Attention Is All You Need" paper (Transformer architecture)
PartyRock.aws - Free playground for Bedrock
Ready to experiment with foundation models? Try PartyRock (it's free!) or dive into the Bedrock playground. Remember, the best way to understand generative AI is to build with it. What will you create first?